The Mesh Beats the Nodes
In 2017, every enterprise architect I knew was deep in the microservices transition. Teams were breaking monoliths into services. Services were multiplying. And everyone was proud of the nodes.
Then the operational reality hit.
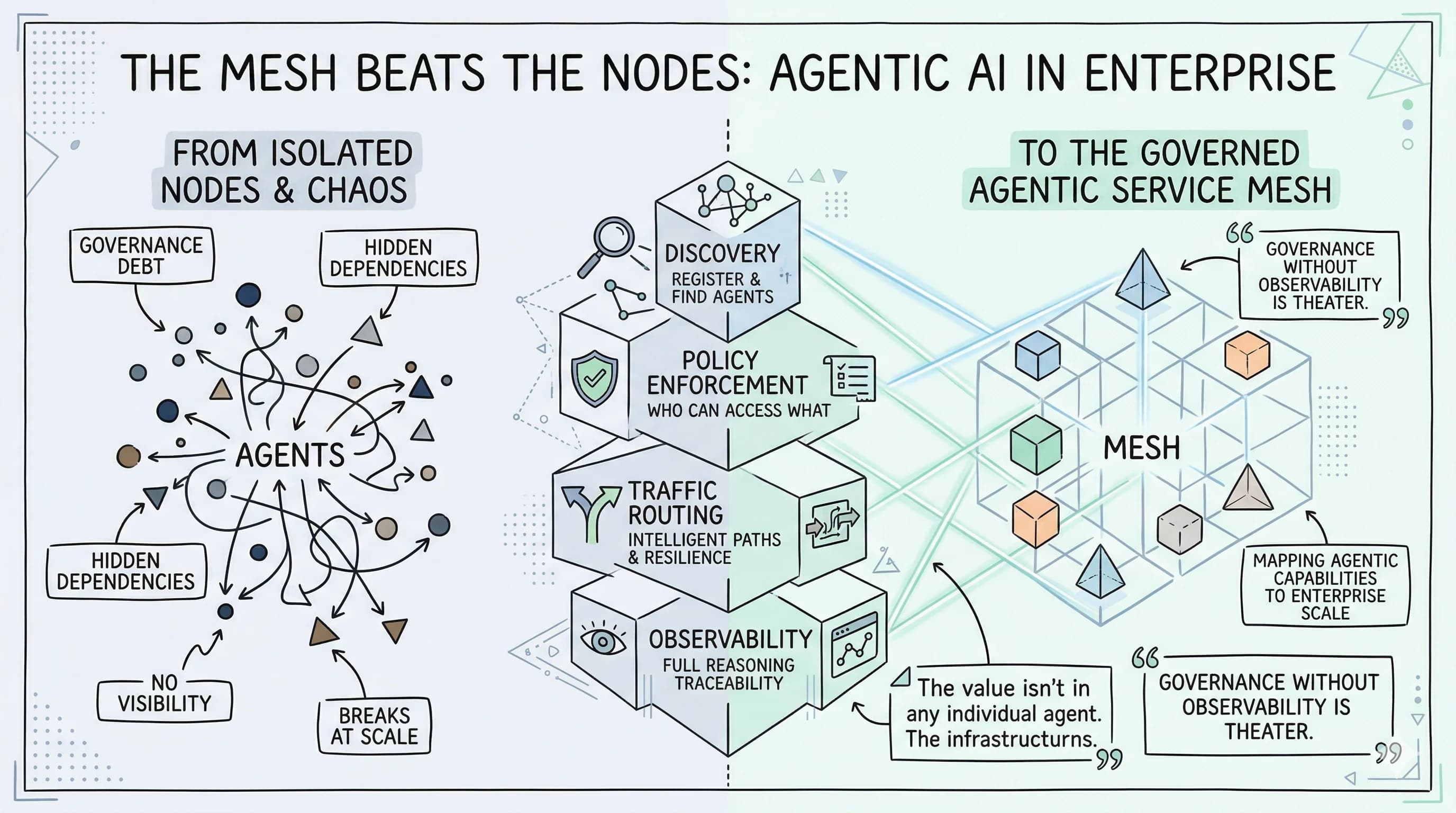
The services worked fine in isolation. But when you had fifty of them talking to each other, things got complicated fast. How do you find a service when you need it? How do you control which services can call which others? What happens when one goes down and takes three others with it? How do you trace a request that touched eleven services before failing on the twelfth?
The services weren't the hard problem. The space between them was.
That insight spawned an entire category: the service mesh. Istio. Consul. Linkerd. Enterprise application platforms built governance layers directly into their runtime — microservice registries, consumer/producer policies, dependency graphs, observability dashboards, scalability controls. Not the nodes — the infrastructure that governed them. Service discovery. Traffic management. Policy enforcement. Distributed tracing. Load balancing. Circuit breakers. Health monitoring. All of it as managed, shared infrastructure rather than code scattered across individual services.
Twitter built their mesh to handle 300,000 queries per second across hundreds of services. Netflix built theirs to manage thousands of microservices across multiple regions. Enterprise customers ran the same pattern at smaller scale — but with the same lesson: the operational complexity lived between the services, not inside them.
Enterprises that skipped the mesh paid for it. They ended up with governance debt — policies living in application code, no visibility into service communication, no way to understand failures, no consistent way to enforce who could call what. The nodes were fine. The system was a mess.
I've been thinking about this a lot lately because I'm watching it happen again.
The Agentic Service Mesh
Bain & Company published a framework this month describing the architecture of enterprise agentic AI platforms. Three layers: application and orchestration, analytics and insight, data and knowledge. Worth reading. But the thing that caught my attention was a concept they slipped into the middle of their orchestration layer without much fanfare: the agentic service mesh.
Four components: governance and trust with agent implementation admin, knowledge routing, adaptive agent allocation, and federated agent discovery.
That's a service mesh. For agents.
And right now, almost no one is building it.
The enterprise AI conversation is almost entirely about the nodes — the agents themselves. Which model are they running on? How fast can they generate? How sophisticated is their reasoning? We're optimizing the services. The space between them is an afterthought.
This is 2017 all over again.
What the Mesh Actually Does
In a microservices architecture, the service mesh handles four things that the services themselves cannot handle efficiently:
Discovery — How does service A find service B without hardcoding addresses? The mesh maintains a live registry, handles routing, manages failures gracefully.
Policy — Which services are allowed to call which others? Who can access what data? Policy lives in the mesh, not in every service's code.
Traffic — Load balancing, retries, circuit breakers, canary routing. The mesh manages how requests flow without requiring each service to implement this logic.
Observability — Distributed tracing across the full call graph. You see every hop, every latency, every failure. Not just "did it work" but "what happened, where, and why."
Now replace "services" with "agents" and read that paragraph again.
Agent discovery — How does an orchestrator know which agents exist, what they're capable of, and whether they're available? Without a managed registry, you either hardcode or you're flying blind.
Agent policy — Which agents can access which data? Which agents are authorized to invoke other agents? Which business rules govern agent behavior in production? Without a policy layer, governance is manual and inconsistent.
Intelligent routing — Which agent is best suited for this task? How do you balance load across multiple agents? How do you gracefully degrade when an agent fails? The orchestration layer needs to handle this without baking it into every workflow.
Full execution traceability — Not just whether an agent ran. The full reasoning path: which prompt triggered which decision, which tool was called, which data was accessed, what the output was, and why. Every step, logged, queryable, auditable.
We've Solved This Before
Here's why I believe the mesh beats the nodes: enterprise software has been proving it for years — not for agents, but for services.
The enterprises running distributed applications on platforms that took this seriously — ours included — got a microservice registry out of the box. Governance rules defining which consumers could access which producers. Observability across the service graph. Scalability controls per service. Dependency tracking so you know what breaks when something changes. Any platform genuinely built for enterprise has this. It's not a differentiator — it's the baseline for operating at scale.
None of that is in the services themselves. It's infrastructure. And the enterprises that have it move faster and break less than the ones that don't.
The pattern is identical for agents. The value isn't in any individual agent. The value is in the infrastructure that lets agents be discovered, governed, composed, observed, and trusted — consistently, across the entire portfolio.
The Part Nobody Is Talking About
Governance without observability is theater.
You can have an agent registry. You can have policy rules. You can have routing logic. But if you can't trace what happened after an agent acted — if you can't answer "what did this agent decide and why, in production, over the last 90 days" — you're not governing anything. You're hoping.
This is the alignment monitoring problem. Not hallucination detection in a test environment. Behavioral drift detection in production. An agent that behaved correctly when you deployed it can drift over time as data changes, as prompt patterns shift, as the world it's operating in evolves around it.
The enterprises that trust their agents will be the ones that can answer three questions:
- Did this agent do what it was authorized to do?
- Did it do it correctly, by my definition of correct?
- Is it still doing it correctly — right now, at scale, in production?
Full reasoning-path traceability is what makes those questions answerable. Every step from prompt to tool call to output, logged and traceable. Not because regulators are asking. Because you can't improve what you can't see.
What This Means If You're Building Today
The enterprise AI teams that win won't be the ones that built the most capable individual agents. They'll be the ones that built the infrastructure underneath them.
The questions worth asking right now:
- Do you have a registry of the agents running in your enterprise — what each one does, what it's authorized to access, what its status is?
- Can you enforce policies on agent-to-agent communication, or is every workflow managing its own access controls?
- Can you trace a decision back through the full reasoning chain, all the way to the prompt and the data that influenced it?
- When an agent's behavior changes, do you detect it — or do you find out from a customer?
If the answer to most of those is "no," you have services without a mesh.
The nodes are the easy part. The enterprises that recognize this early will be years ahead of the ones that figure it out after the governance debt compounds.
We've been here before. The lesson didn't change.
The mesh beats the nodes.
- The operational complexity in agentic AI lives between the agents — in discovery, policy, routing, and observability — not inside any individual agent.
- Governance without observability is theater. Behavioral drift detection in production is the real alignment challenge, not hallucination tests in a lab.
- The value isn't in building the most capable individual agents. It's in the infrastructure that lets agents be discovered, governed, composed, and trusted at scale.
- Enterprises that skip the mesh will accumulate governance debt — just like the ones that skipped service mesh in 2017. The lesson didn't change.
Building enterprise agentic systems? I'd love to hear what governance problems you're hitting in production — or what's working.
#AgenticAI #EnterpriseAI #Microservices #AIGovernance #ProductLeadership